Japanese Fake News Dataset

Overview
Fake news has caused significant damage to various fields of society, e.g., economy, politics, and health problems. To counter this problem, various fake news datasets have been constructed. These existing datasets have focused almost exclusively on the factuality aspect of the news. Can we fully understand “fake news” and various events it causes based on these datasets given factuality labels? This is exactly the motivation behind our dataset construction. To promote understanding of fake news, we consider it is necessary to provide not only factual information but also information from various perspectives; the intention of the false news disseminator, the harmfulness of the news to our society, the target of the news, etc. We built a novel annotation scheme with fine-grained labeling to capture the various aspects of fake news, which is built based on the detailed investigations of existing fake news datasets. We then construct the first Japanese fake news dataset according to the annotation scheme. Our dataset can be expected to bring us in-depth understanding of fake news.
Dataset Description
Our dataset includes 307 news stories, which were verified by Fact Check Initiative Japan between July 2019 and October 2021. We provide our dataset in two folders: One is Label folder, which contains label information by our annotation and fact-checking URLs. Another is Tweet folder, which contains the collected tweet IDs related to each news.
Our dataset is published at https://zenodo.org/record/5831617
-
Label folder
This folder contains our annotation labels to each news. It is composed of two files.-
label.csv
This file composes of and ID, article names, URL, and our annotation labels. The file is tsv format, whose column names are below:ID Article URL Q1 Q2-1 Q2-2A Q2-2B Q4 Q5 Q6 Q7
-
q3-*.csv
We provide the label for Q3 assigned by each annotator. The file is tsv format, whose column names are below:ID Q3
-
-
Tweet folder
This folder contains the collected tweet IDs related to each news. In a folder for each news item named news ID, there are two types of posts: one (FS) is tweetIDs related to the original news item and another (FC) is tweets related to the fact-checking article.
Additionally, we provide three types of tweet information by separate file:- Tweet IDs (tweet)
- User IDs (user)
- Conversation IDs (conv)
But, each news folder does not always have all these files because of the removal.
When we have, in News ID “21”, a list of tweet IDs and user IDs for the original news article (FS) and a list of tweet IDs and user IDs for the fact-checking article related to it (FC), our file structure would be below:Tweet/21/FS-21-tweet.txt
Tweet/21/FS-21-user.txt
Tweet/21/FC-21-tweet.txt
Tweet/21/FC-21-user.txt
Paper
Read our arXiv paper for more details here
If you use this dataset, please cite
@article{murayama2022annotation, title={Annotation-Scheme Reconstruction for" Fake News" and Japanese Fake News Dataset}, author={Murayama, Taichi and Hisada, Shohei and Uehara, Makoto and Wakamiya, Shoko and Aramaki, Eiji}, journal={arXiv preprint arXiv:2204.02718}, year={2022} }
Existing dataset list
We examined 51 fake news detection datasets and identified several issues that needed to be resolved for dataset constructuion. Each dataset are listed in below.
Read our arXiv paper for more detailed descriptions of each dataset: https://arxiv.org/abs/2111.03299
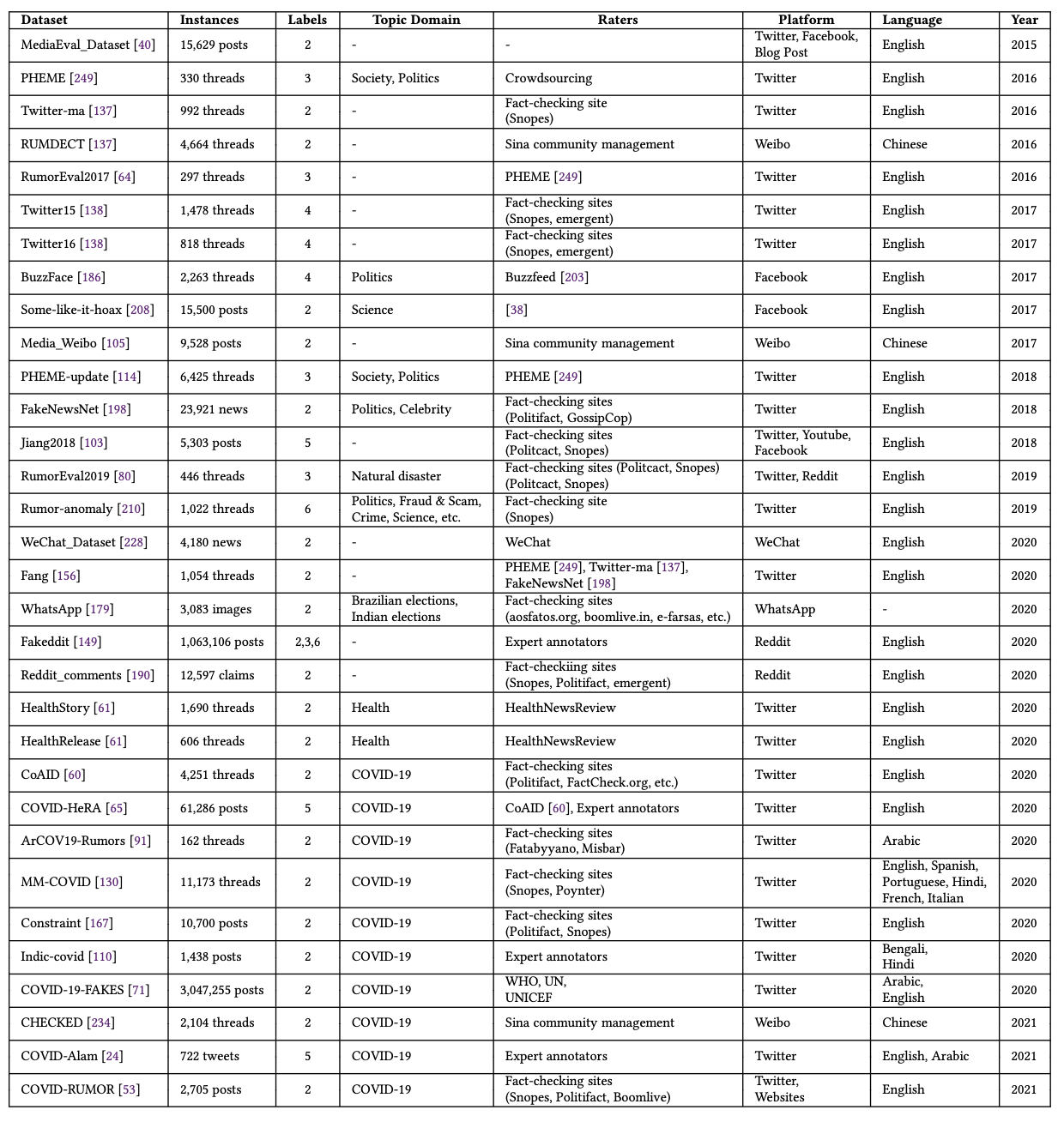
Fake News Detection Dataset on news articles
-
Politifact14
Andreas Vlachos and Sebastian Riedel. 2014. Fact checking: Task definition and dataset construction. InProceedings of the ACL 2014 Workshop onLanguage Technologies and Computational Social Science. 18–22.
-
Buzzfeed_political
-
Random_political
Benjamin D Horne and Sibel Adali. 2017. This Just In: Fake News Packs a Lot in Title, Uses Similar, Repetitive Contentin Text Body, More Similarto Satire than Real News. InProceedings of the 2nd International Workshop on News and Public Opinion at ICWSM.
-
Ahmed2017
Hadeer Ahmed, Issa Traore, and Sherif Saad. 2017. Detection of online fake news using n-gram analysis and machine learning techniques. InInternational conference on intelligent, secure, and dependable systems in distributed and cloud environments. Springer, 127–138.
-
LIAR
Tariq Alhindi, Savvas Petridis, and Smaranda Muresan.2018. Where is your Evidence: Improving Fact-checking by Justification Modeling. InProceedings of the First Workshop on Fact Extraction and VERification (FEVER). 85–90. William Yang Wang. 2017. “Liar, Liar Pants on Fire”: A New Benchmark Dataset for Fake News Detection. InProceedings of the 55th AnnualMeeting of the Association for Computational Linguistics (Volume 2: Short Papers). 422–426.
-
TSHP-17_politifac
Hannah Rashkin, Eunsol Choi, Jin Yea Jang, Svitlana Volkova, and Yejin Choi. 2017. Truth of varying shades: Analyzing language in fake newsand political fact-checking. InProceedings of the 2017 conference on empirical methods in natural language processing. 2931–2937.
-
FakeNewsAMT
-
Celebrity
Verónica Pérez-Rosas, Bennett Kleinberg, AlexandraLefevre, and Rada Mihalcea. 2018. Automatic Detection of Fake News. InProceedings of the27th International Conference on Computational Linguistics. 3391–3401.
-
Kaggle_UTK
TK Machine Learning Club. 2018. Fake News: Build a system to identify unreliable news articles. https://www.kaggle.com/c/fake-news.
-
MisInfoText_Buzzfeed
-
MisInfoText_Snopes
Fatemeh Torabi Asr and Maite Taboada. 2019. Big Data and quality data for fake news and misinformation detection.Big Data & Society6, 1(2019), 2053951719843310
-
FA-KES
Fatima K Abu Salem, Roaa Al Feel, Shady Elbassuoni, Mohamad Jaber, and May Farah. 2019. Fa-kes: A fake news dataset around the syrian war.InProceedings of the International AAAI Conference on Web and Social Media, Vol. 13. 573–582.
-
Spanish-v1
-
Spanish-v2 Juan-Pablo Posadas-Durán, Helena Gómez-Adorno, Grigori Sidorov, and Jesús Jaime Moreno Escobar. 2019. Detection of fake news in a newcorpus for the Spanish language.Journal of Intelligent & Fuzzy Systems36, 5 (2019), 4869–4876.
-
fauxtography
Dimitrina Zlatkova, Preslav Nakov, and Ivan Koychev.2019. Fact-Checking Meets Fauxtography: Verifying ClaimsAbout Images. InProceedings ofthe 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing(EMNLP-IJCNLP). Association for Computational Linguistics, 2099–2108.
-
Breaking!
Subhabrata Mukherjee and Gerhard Weikum. 2015. Leveraging joint interactions for credibility analysis in news communities. InProceedings ofthe 24th ACM International on Conference on Information andKnowledge Management. 353–362
-
TDS2020
Ria Gandhi. 2020. Getting Real with Fake News. https://towardsdatascience.com/getting-real-with-fake-news-d4bc033eb38a
-
FakeCovid
Gautam Kishore Shahi and Durgesh Nandini. 2020. FakeCovid – A Multilingual Cross-domain Fact Check News Dataset for COVID-19. InWorkshop Proceedings of the 14th International AAAI Conference on Web and Social Media.
-
TrueFact_FND KDD 2020 TrueFact Workshop: Making a Credible Webfor Tomorrow: Shared Task 2. https://www.microsoft.com/en-us/research/event/kdd-2020-truefact-workshop-making-a-credible-web-for-tomorrow/#!shared-tasks
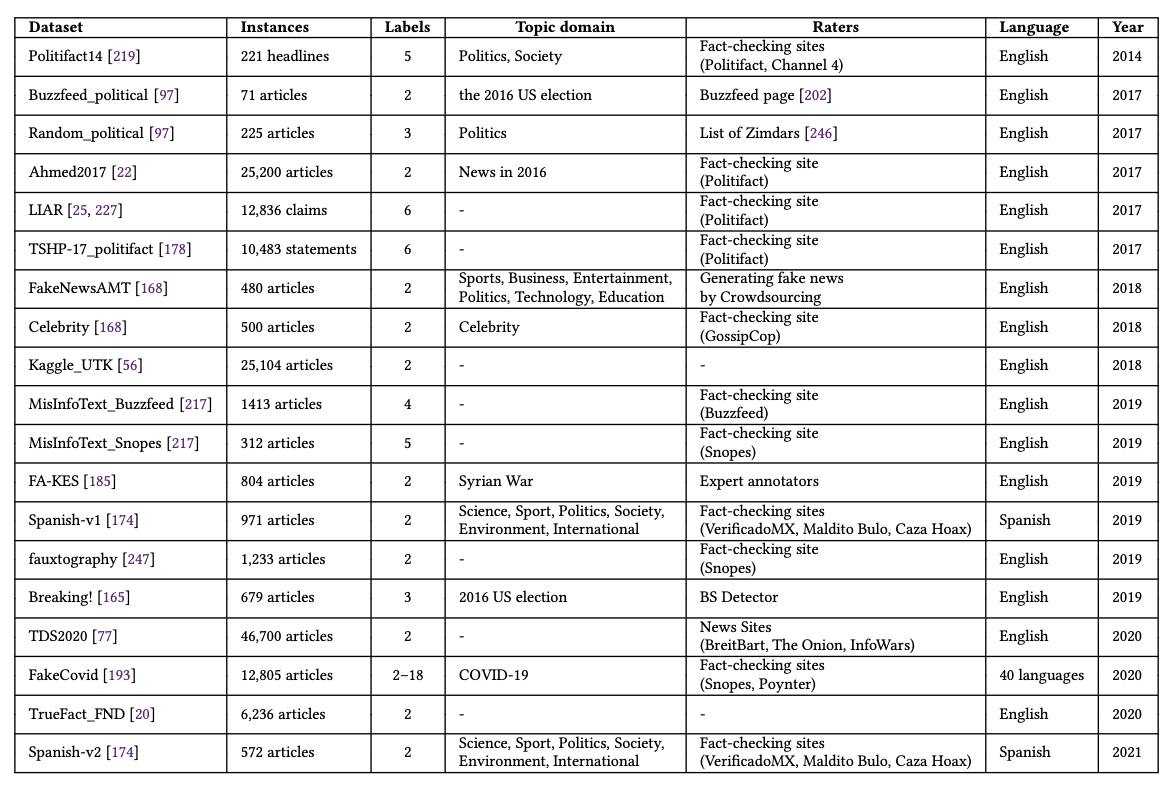
Fake News Detection Dataset on social media posts
-
MediaEval_Dataset
Christina Boididou, Symeon Papadopoulos, Markos Zampoglou, Lazaros Apostolidis, Olga Papadopoulou, and Yiannis Kompatsiaris. 2018. Detec-tion and visualization of misleading content on Twitter.International Journal of Multimedia Information Retrieval7, 1 (2018), 71–86.
-
PHEME
Arkaitz Zubiaga, Maria Liakata, Rob Procter, Geraldine Wong Sak Hoi, and Peter Tolmie. 2016. Analysing how peopleorient to and spreadrumours in social media by looking at conversational threads.PloS one11, 3 (2016), e0150989.
-
Twitter-ma
-
RUMDECT
Jing Ma, Wei Gao, Prasenjit Mitra, Sejeong Kwon, Bernard J. Jansen, Kam-Fai Wong, and Meeyoung Cha. 2016. Detecting Rumors from Microblogswith Recurrent Neural Networks(IJCAI’16). 3818–3824
-
RumorEval2017
Leon Derczynski, Kalina Bontcheva, Maria Liakata, RobProcter, Geraldine Wong Sak Hoi, and Arkaitz Zubiaga. 2017.SemEval-2017 Task 8:RumourEval: Determining rumour veracity and support for rumours. InProceedings of the 11th International Workshop on Semantic Evaluation(SemEval-2017). 69–76.
-
Twitter15
-
Twitter16
Jing Ma, Wei Gao, and Kam-Fai Wong. 2017. Detect Rumorsin Microblog Posts Using Propagation Structure via Kernel Learning. InProceedingsof the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 708–717.
-
BuzzFace
Giovanni C Santia and Jake Ryland Williams. 2018. Buzzface: A news veracity dataset with facebook user commentaryand egos. InProceedingsof the 12th International AAAI Conference on Web and Social Media.
-
Some-like-it-hoax
Eugenio Tacchini, Gabriele Ballarin, Marco L Della Vedova, Stefano Moret, and Luca de Alfaro. 2017. Some like it Hoax: Automated fake newsdetection in social networks. In2nd Workshop on Data Science for Social Good, SoGood 2017. CEUR-WS, 1–15.
-
Media_Weibo
Zhiwei Jin, Juan Cao, Han Guo, Yongdong Zhang, and Jiebo Luo. 2017. Multimodal fusion with recurrent neural networks for rumor detectionon microblogs. InProceedings of the 25th ACM international conference on Multimedia. 795–816.
-
PHEME-update
Elena Kochkina, Maria Liakata, and Arkaitz Zubiaga. 2018. All-in-one: Multi-task Learning for Rumour Verification. InProceedings of the 27thInternational Conference on Computational Linguistics. 3402–3413.
-
FakeNewsNet
Kai Shu, Deepak Mahudeswaran, Suhang Wang, Dongwon Lee, and Huan Liu. 2020. FakeNewsNet: A Data Repository with News Content, SocialContext, and Spatiotemporal Information for Studying FakeNews on Social Media.Big Data8, 3 (2020), 171–188.
-
Jiang2018
Shan Jiang and Christo Wilson. 2018. Linguistic signals under misinformation and fact-checking: Evidence from user comments on social media.Proceedings of the ACM on Human-Computer Interaction2, CSCW (2018), 1–23.
-
RumorEval2019
Genevieve Gorrell, Elena Kochkina, Maria Liakata, Ahmet Aker, Arkaitz Zubiaga, Kalina Bontcheva, and Leon Derczynski. 2019. SemEval-2019Task 7: RumourEval, Determining Rumour Veracity and Support for Rumours. InProceedings of the 13th International Workshop on SemanticEvaluation. 845–854.
-
Rumor-anomaly
Nguyen Thanh Tam, Matthias Weidlich, Bolong Zheng, Hongzhi Yin, Nguyen Quoc Viet Hung, and Bela Stantic. 2019. From anomaly detectionto rumour detection using data streams of social platforms.Proceedings of the VLDB Endowment12, 9 (2019), 1016–1029.
-
WeChat-Dataset
Yaqing Wang, Weifeng Yang, Fenglong Ma, Jin Xu, Bin Zhong, Qiang Deng, and Jing Gao. 2020. Weak supervision for fakenews detection viareinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 516–523.
-
Fang
Van-Hoang Nguyen, Kazunari Sugiyama, Preslav Nakov,and Min-Yen Kan. 2020. FANG: Leveraging Social Context for Fake News DetectionUsing Graph Representation. InProceedings of the 29th ACM International Conference on Information and Knowledge Management. 1165–1174.
-
WhatsApp
Julio CS Reis, Philipe Melo, Kiran Garimella, JussaraM Almeida, Dean Eckles, and Fabrício Benevenuto. 2020. A Dataset of Fact-Checked ImagesShared on WhatsApp During the Brazilian and Indian Elections. InProceedings of the International AAAI Conference on Web and Social Media,Vol. 14. 903–908.
-
Fakeddit
Kai Nakamura, Sharon Levy, and William Yang Wang. 2020. Fakeddit: A New Multimodal Benchmark Dataset for Fine-grained Fake NewsDetection. InProceedings of the 12th Language Resources and Evaluation Conference. 6149–6157.
-
Reddit_comments
Vinay Setty and Erlend Rekve. 2020. Truth be Told: FakeNews Detection Using User Reactions on Reddit. InProceedings of the 29th ACMInternational Conference on Information and Knowledge Management. 3325–3328.
-
HealthStory
-
HealthRelease
Enyan Dai, Yiwei Sun, and Suhang Wang. 2020. Ginger cannot cure cancer: Battling fake health news with a comprehensive data repository. InProceedings of the International AAAI Conference on Web and Social Media, Vol. 14. 853–862.
-
CoAID
Limeng Cui and Dongwon Lee. 2020. Coaid: Covid-19 healthcare misinformation dataset.arXiv preprint arXiv:2006.00885(2020).
-
COVID-HeRA
Arkin Dharawat, Ismini Lourentzou, Alex Morales, and ChengXiang Zhai. 2020. Drink bleach or do what now? covid-hera: A dataset for risk-informed health decision making in the presence of covid19 misinformation.arXiv preprint arXiv:2010.08743(2020).
-
ArCOV19-Rumors
Fatima Haouari, Maram Hasanain, Reem Suwaileh, and Tamer Elsayed. 2021. ArCOV19-Rumors: Arabic COVID-19 TwitterDataset for Misinfor-mation Detection. InProceedings of the Sixth Arabic Natural Language Processing Workshop. 72–81.
-
MM-COVID
Yichuan Li, Bohan Jiang, Kai Shu, and Huan Liu. 2020. MM-COVID: A multilingual and multimodal data repository for combating COVID-19disinformation.arXiv preprint arXiv:2011.04088(2020).
-
Constraint
Parth Patwa, Shivam Sharma, Srinivas PYKL, Vineeth Guptha, Gitanjali Kumari, Md Shad Akhtar, Asif Ekbal, AmitavaDas, and TanmoyChakraborty. 2020. Fighting an Infodemic: COVID-19 Fake News Dataset.arXiv preprint arXiv:2011.03327(2020).
-
Indic-covid
Debanjana Kar, Mohit Bhardwaj, Suranjana Samanta, and Amar Prakash Azad. 2020. No rumours please! A multi-indic-lingual approach forCOVID fake-tweet detection.arXiv preprint arXiv:2010.06906(2020).
-
COVID-19-FAKES
Mohamed K Elhadad, Kin Fun Li, and Fayez Gebali. 2020. COVID-19-FAKES: A twitter (Arabic/English) dataset for detecting misleading informa-tion on COVID-19. InInternational Conference on Intelligent Networking and Collaborative Systems. Springer, 256–268.
-
CHECKED
Chen Yang, Xinyi Zhou, and Reza Zafarani. 2021. CHECKED: Chinese COVID-19 fake news dataset.Social Network Analysis and Mining11, 1(2021), 1–8.
-
COVID-Alam
Firoj Alam, Fahim Dalvi, Shaden Shaar, Nadir Durrani, Hamdy Mubarak, Alex Nikolov, Giovanni Da San Martino, Ahmed Abdelali, Hassan Sajjad,Kareem Darwish, et al. 2021. Fighting the COVID-19 Infodemic in Social Media: A Holistic Perspective and a Call to Arms. InProceedings of theInternational AAAI Conference on Web and Social Media, Vol. 15. 913–922.
-
COVID-RUMOR
Mingxi Cheng, Songli Wang, Xiaofeng Yan, Tianqi Yang, Wenshuo Wang, Zehao Huang, Xiongye Xiao, Shahin Nazarian, and Paul Bogdan. 2021.A COVID-19 Rumor Dataset.Frontiers in Psychology12 (2021).